HackTheBox - Exploitation
Write-up du module Exploitation

Informations sur la room
Découvrez le cours HTB sur l’Exploitation
Lien : Exploitation
Objectifs d’apprentissage
Cette room couvre les compétences suivantes :
- Comprendre la phase d’exploitation lors d’un test d’intrusion
Exploitation
Lors de la phase d'exploitation, nous recherchons des moyens d’adapter ces vulnérabilités à notre cas d’utilisation afin d’obtenir le rôle souhaité (par exemple, un accès au système, une élévation de privilèges, etc.). Si nous voulons obtenir un reverse-shell, nous devons modifier la preuve de concept (PoC) pour exécuter le code, de sorte que le système cible se connecte à nous via une connexion (idéalement) chiffrée à une adresse IP que nous spécifions. Par conséquent, la préparation d’un exploit constitue l’essentiel de la phase d’exploitation.
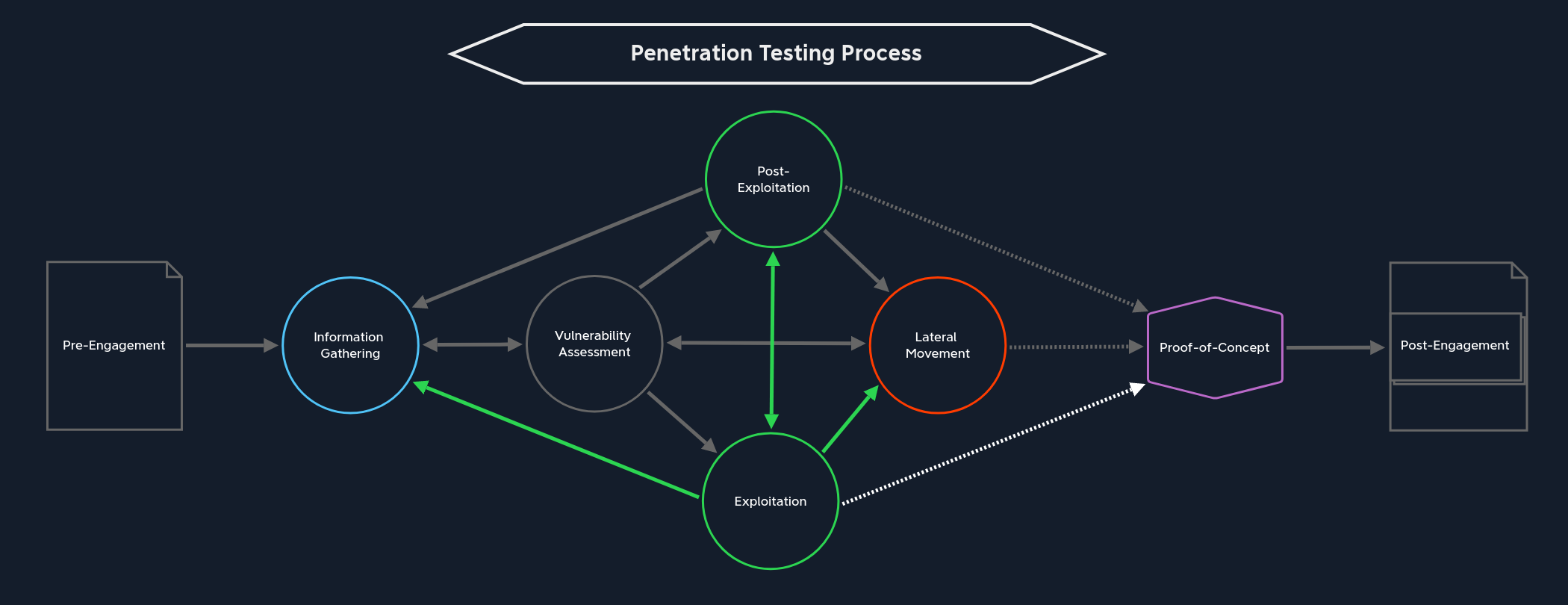
Ces étapes ne doivent pas être strictement cloisonnées, car elles sont étroitement liées. Il est néanmoins important de bien distinguer la phase en cours et son objectif. En effet, par la suite, avec des processus beaucoup plus complexes et un volume d’informations bien plus important, il est très facile de perdre le fil des étapes franchies, surtout si le test d’intrusion dure plusieurs semaines et couvre un vaste périmètre.
Prioritization of Possible Attacks
Une fois que nous avons identifié une ou deux vulnérabilités lors de l’évaluation des vulnérabilités et que nous pouvons les exploiter sur notre réseau/système cible, nous pouvons prioriser les attaques. Le choix de la priorité dépend des facteurs suivants :
- Probabilité de succès
- Complexité
- Probabilité de dommages
Tout d’abord, il est nécessaire d'évaluer la probabilité de succès d’une attaque donnée contre la cible. Le score CVSS peut nous y aider, notamment grâce au calculateur NVD, afin d’estimer les attaques spécifiques et leur probabilité de succès.
La complexité représente l’effort requis pour exploiter une vulnérabilité particulière. Elle permet d’estimer le temps, les efforts et les recherches nécessaires à la réussite de l’attaque. Notre expérience est primordiale : toute attaque inédite exigera logiquement davantage de recherches et d’efforts, car il est indispensable de comprendre en détail l’attaque et la structure de l’exploit avant de l’appliquer.
L’estimation de la probabilité de dommages causés par l’exécution d’un exploit est cruciale, car nous devons éviter tout dommage aux systèmes cibles. En règle générale, nous n’effectuons pas d’attaques par déni de service (DoS) sauf demande expresse du client. Néanmoins, attaquer des services en production avec des exploits susceptibles d’endommager le logiciel ou le système d’exploitation est une pratique à proscrire absolument.
De plus, nous pouvons attribuer ces facteurs à un système de points personnel qui permettra de calculer l’évaluation avec plus de précision en fonction de nos compétences et de nos connaissances :
Prioritization Example
| Facteur | Points | Remote File Inclusion | Buffer Overflow |
|---|---|---|---|
| 1. Probability of Success | 10 | 10 | 8 |
| 2. Complexity - Easy | 5 | 5 | 4 |
| 3. Complexity - Medium | 3 | 0 | 3 |
| 4. Complexity - Hard | 1 | 0 | 0 |
| 5. Probability of Damage | -5 | 0 | -5 |
| Summary | max. 15 | 14 | 6 |
D’après l’exemple précédent, nous privilégions l’attaque par inclusion de fichier distant. Elle est facile à préparer et à exécuter et ne devrait causer aucun dommage si elle est menée avec précaution.
Preparation for the Attack
Il arrive parfois que nous ne trouvions pas de code d’exploitation PoC fonctionnel et de haute qualité. Dans ce cas, il peut être nécessaire de reconstruire l’exploit localement sur une machine virtuelle (VM) représentant notre hôte cible afin de déterminer précisément les éléments à adapter et à modifier. Une fois le système configuré localement et les composants connus installés pour reproduire au mieux l’environnement cible (par exemple, mêmes numéros de version pour les services et applications cibles), nous pouvons commencer la préparation de l’exploit en suivant les étapes décrites. Nous le testons ensuite sur une VM hébergée localement pour nous assurer de son bon fonctionnement et de l’absence de dommages importants. Dans d’autres situations, nous rencontrons des erreurs de configuration et des vulnérabilités que nous observons fréquemment. Nous savons alors précisément quel outil ou exploit utiliser et si l’exploit ou la technique est « sûr » ou susceptible d’entraîner une instabilité.
En cas de doute avant de lancer une attaque, il est toujours préférable de consulter notre client et de lui fournir toutes les données nécessaires afin qu’il puisse décider en toute connaissance de cause s’il souhaite que nous tentions l’exploitation ou si nous nous contentons de signaler le problème. S’ils choisissent que nous n’effectuions pas l’exploitation, nous pouvons indiquer dans le rapport que cela n’a pas été confirmé activement, mais qu’il s’agit probablement d’un problème à résoudre. Nous disposons d’une certaine marge de manœuvre lors des tests d’intrusion et devons toujours faire preuve de discernement si une attaque particulière semble trop risquée ou susceptible de provoquer une interruption de service. En cas de doute, communiquez. Votre responsable d’équipe/gestionnaire, le client, préférera certainement une communication plus approfondie plutôt que de se retrouver dans une situation où ils tentent de remettre un système en ligne après une tentative d’exploitation infructueuse.
Une fois que nous aurons exploité une cible avec succès et obtenu un accès initial (après avoir pris des notes claires pour nos rapports et consigné toutes les activités dans notre journal d’activité !), nous passerons aux phases de post-exploitation et de déplacement latéral.
Post-Exploitation
Supposons que nous ayons réussi à exploiter le système cible lors de la phase d'exploitation. Comme lors de cette phase, nous devons à nouveau nous interroger sur l’opportunité d’utiliser des tests d'évasion lors de la phase de post-exploitation. Étant donné que nous sommes déjà présents sur le système lors de cette phase, il est beaucoup plus difficile d’éviter une alerte. La phase de post-exploitation vise à obtenir des informations sensibles et pertinentes pour la sécurité d’un point de vue local, ainsi que des informations pertinentes pour l’entreprise qui, dans la plupart des cas, requièrent des privilèges supérieurs à ceux d’un utilisateur standard. Cette phase comprend les composants suivants :
- Evasive Testing
- Information Gathering
- Pillaging
- Vulnerability Assessment
- Privilege Escalation
- Persistence
- Data Exfiltration
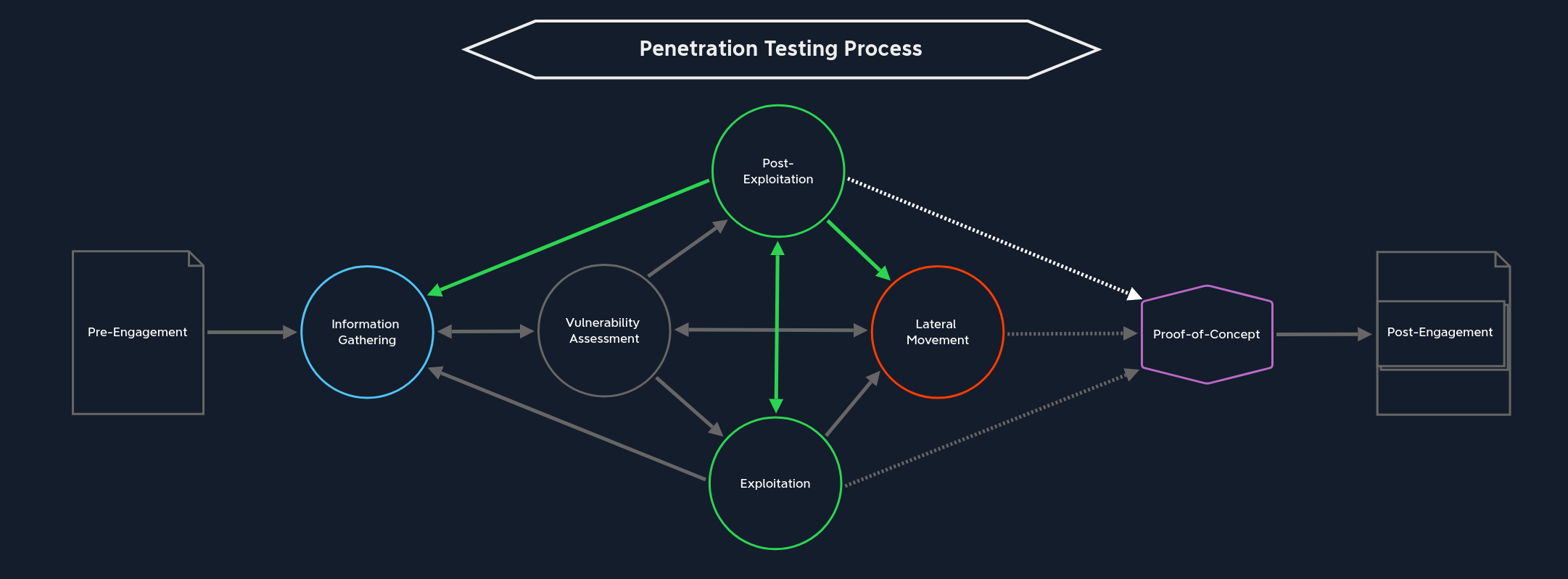
Evasive Testing
Si un administrateur système compétent surveille les systèmes, la moindre modification, voire une simple commande, pourrait déclencher une alarme et nous trahir. Dans de nombreux cas, nous sommes expulsés du réseau, et la recherche de menaces commence alors, nous plaçant ainsi au centre des préoccupations. Nous pouvons également perdre l’accès à un hôte (mis en quarantaine) ou à un compte utilisateur (temporairement désactivé ou dont le mot de passe est modifié). Ce test d’intrusion aurait échoué, mais aurait été concluant d’une certaine manière, car le client a pu détecter certaines actions. Nous pouvons apporter une valeur ajoutée au client dans cette situation en documentant l’intégralité de la chaîne d’attaque et en l’aidant à identifier les failles de sa surveillance et de ses processus, là où il n’a pas repéré nos agissements. De notre côté, nous pouvons analyser comment et pourquoi le client nous a détectés et travailler à l’amélioration de nos techniques d’évasion. Il se peut que nous n’ayons pas testé une charge utile de manière approfondie, ou que nous ayons commis une négligence en exécutant une commande telle que « net user » ou « whoami », souvent surveillée par les systèmes EDR et signalée comme une activité anormale.
Il est souvent utile pour nos clients d’exécuter des commandes ou des outils que leurs défenses bloquent ou détectent. Cela leur prouve que leurs systèmes de défense fonctionnent face à certaines attaques. Il est important de noter que nous simulons un attaquant; par conséquent, il n’est pas toujours négatif que certaines attaques soient détectées. Toutefois, lors de tests d’évasion, notre objectif doit être de rester quasiment indétectables afin d’identifier les failles potentielles de l’environnement réseau de nos clients.
Les tests d’évitement se divisent en trois catégories différentes:
- Evasive
- Hybrid Evasive
- Non-Evasive
Cela ne signifie pas que nous ne pouvons pas utiliser les trois méthodes. Supposons que notre client souhaite réaliser un test d’intrusion intrusif afin d’obtenir un maximum d’informations et des résultats de test approfondis. Dans ce cas, nous effectuerons des tests non invasifs, car les mesures de sécurité du réseau peuvent nous limiter, voire nous empêcher. Toutefois, ces tests peuvent être combinés à des tests invasifs, en utilisant les mêmes commandes et méthodes. Nous pouvons ainsi vérifier si les mesures de sécurité sont capables d’identifier les actions effectuées et d’y répondre. Dans le cadre de tests hybrides invasifs, nous pouvons tester des composants et des mesures de sécurité spécifiques, définis au préalable. Cette approche est courante lorsque le client souhaite tester uniquement certains services ou serveurs afin de vérifier leur résistance aux attaques.
Information Gathering
Puisque la phase d’exploitation nous a permis d’acquérir une nouvelle perspective sur le système et le réseau de notre système cible, nous nous trouvons dans un environnement fondamentalement nouveau. Il nous faut donc nous familiariser à nouveau avec les éléments dont nous disposons et les options qui s’offrent à nous. Par conséquent, lors de la phase de post-exploitation, nous reprenons les phases de collecte d’informations et d’évaluation des vulnérabilités, que l’on peut considérer comme faisant partie intégrante de la phase actuelle. En effet, les informations dont nous disposions jusqu’à présent provenaient d’une perspective externe, et non interne.
D’un point de vue interne (local), nous avons accès à un plus grand nombre de possibilités et d’alternatives pour accéder aux informations pertinentes. La phase de collecte d’informations recommence donc entièrement, toujours d’un point de vue local. Nous recherchons et collectons autant d’informations que possible. La différence réside ici dans le fait que nous recensons également le réseau local et les services locaux tels que les imprimantes, les serveurs de bases de données, les services de virtualisation, etc. Nous découvrons souvent des partages destinés aux employés pour l’échange de données et de fichiers. L’investigation de ces services et composants réseau est appelée « pillage ».
Pillaging
L'étape de pillage consiste à examiner le rôle de l’hôte au sein du réseau d’entreprise. Nous analysons les configurations réseau, notamment :
- Interfaces
- Routing
- DNS
- ARP
- Services
- VPN
- IP Subnets
- Shares
- Network Traffic
Comprendre le rôle du système sur lequel nous nous trouvons nous permet également de mieux appréhender son mode de communication avec les autres périphériques réseau et sa finalité. Nous pouvons ainsi déterminer, par exemple, quels sous-domaines alternatifs existent, s’il possède plusieurs interfaces réseau, s’il communique avec d’autres hôtes, si des administrateurs s’y connectent, et si nous pouvons potentiellement réutiliser des identifiants ou voler une clé SSH pour étendre notre accès ou établir une connexion persistante, etc. Cela nous aide surtout à obtenir une vue d’ensemble de la structure du réseau.
Par exemple, nous pouvons utiliser les politiques installées sur ce système pour déterminer celles utilisées par les autres hôtes du réseau. En effet, les administrateurs utilisent souvent des schémas spécifiques pour sécuriser leur réseau et empêcher les utilisateurs d’y apporter des modifications. Supposons, par exemple, que nous découvrions que la politique de mot de passe n’exige que huit caractères, sans caractères spéciaux. Dans ce cas, nous pouvons conclure qu’il est relativement probable que nous puissions deviner les mots de passe d’autres utilisateurs sur ce système et d’autres.
Lors de la phase de pillage, nous rechercherons également des données sensibles telles que les mots de passe sur les partages, les machines locales, dans les scripts, les fichiers de configuration, les gestionnaires de mots de passe, les documents (Excel, Word, fichiers .txt, etc.) et même les courriels.
Nos principaux objectifs sont de démontrer l’impact d’une exploitation réussie et, si l’objectif de l’évaluation n’est pas encore atteint, de trouver des données supplémentaires, comme des mots de passe, qui pourront servir d’entrée pour d’autres phases, telles que les déplacements latéraux.
Persistence
Une fois que nous avons une vue d’ensemble du système, notre prochaine étape consiste à maintenir l’accès à l’hôte compromis. Ainsi, même en cas d’interruption de la connexion, nous pourrons y accéder. Cette étape est essentielle et constitue souvent la première étape avant les phases de collecte d'informations et d'exploitation des données.
Il est important de suivre des séquences non standardisées, car chaque système est configuré individuellement par un administrateur qui apporte ses propres préférences et connaissances. Il est recommandé de faire preuve de flexibilité durant cette phase et de s'adapter aux circonstances. Par exemple, supposons que nous ayons utilisé une attaque par dépassement de tampon sur un service susceptible de le faire planter. Dans ce cas, nous devons établir une persistance sur le système dès que possible afin d’éviter de devoir attaquer le service à plusieurs reprises et de potentiellement provoquer une interruption de service. Bien souvent, si nous perdons la connexion, nous ne pourrons plus accéder au système de la même manière.
Vulnerability Assessment
Si nous conservons l’accès au système et une bonne vue d’ensemble, nous pouvons utiliser les informations le concernant, ainsi que ses services et toutes les autres données stockées, pour répéter l'évaluation des vulnérabilités, cette fois-ci depuis l’intérieur du système. Nous analysons ces informations et les hiérarchisons en conséquence. Notre objectif suivant est l’élévation de privilèges (si elle n’est pas déjà en place).
Il est essentiel de distinguer les exploits susceptibles de nuire au système des attaques contre les services qui ne provoquent aucune interruption. Pour ce faire, nous pondérons les éléments déjà analysés lors de la première évaluation des vulnérabilités.
Privilege Escalation
L’élévation de privilèges est un processus important qui, dans la plupart des cas, représente un tournant décisif pouvant ouvrir de nouvelles perspectives. Obtenir les privilèges les plus élevés possibles sur le système ou le domaine est souvent crucial. C’est pourquoi nous cherchons à obtenir les privilèges de l’utilisateur root (sur les systèmes Linux) ou ceux de l’administrateur de domaine/administrateur local/SYSTEM (sur les systèmes Windows), car cela nous permet généralement de circuler librement sur l’ensemble du réseau.
Il est toutefois essentiel de se rappeler que l’élévation de privilèges ne se limite pas toujours à un usage local. Nous pouvons également obtenir des identifiants stockés lors de la phase de collecte d’informations auprès d’autres utilisateurs appartenant à un groupe disposant de privilèges supérieurs. Exploiter ces privilèges pour se connecter en tant qu’autre utilisateur fait également partie de l’élévation de privilèges, car nous avons ainsi étendu nos privilèges (rapidement) grâce à ces nouveaux identifiants.
Data Exfiltration
Lors de la phase de collecte et d’analyse des données, nous sommes souvent en mesure de découvrir, entre autres, d’importantes informations personnelles et des données clients. Certains clients souhaitent vérifier la possibilité d'exfiltrer ces données. Cela signifie que nous tentons de transférer ces informations du système cible vers le nôtre. Les systèmes de sécurité tels que la prévention des pertes de données (DLP) et la détection et la réponse aux incidents sur les terminaux (EDR) contribuent à détecter et à prévenir l’exfiltration de données. Outre la surveillance du réseau, de nombreuses entreprises utilisent le chiffrement des disques durs pour empêcher les tiers d’accéder à ces informations. Avant toute exfiltration de données réelles, nous devons obtenir l’accord du client et de notre responsable. Il peut souvent suffire de créer de fausses données (comme de faux numéros de carte de crédit ou de sécurité sociale) et de les exfiltrer vers notre système. De cette manière, les mécanismes de protection qui analysent les flux de données sortants du réseau sont testés, sans que nous soyons responsables des données sensibles présentes sur notre machine de test.
Les entreprises doivent se conformer aux réglementations en matière de sécurité des données, qui varient selon le type de données concernées. Ces réglementations incluent, sans s’y limiter :
| Type d’information | Réglementation de sécurité |
|---|---|
| Credit Card Account Information | Payment Card Industry (PCI) |
| Electronic Patient Health Information | Health Insurance Portability and Accountability Act (HIPAA) |
| Consumers Private Banking Information | Gramm-Leach-Bliley (GLBA) |
| Government Information | Federal Information Security Management Act of 2002 (FISMA) |
Voici quelques exemples de cadres de référence que les entreprises peuvent suivre :
- (NIST) - National Institute of Standards and Technology
- (CIS Controls) - Center for Internet Security Controls
- (ISO) - International Organization for Standardization
- (PCI-DSS) - The Payment Card Industry Data Security Standard
- (GDPR) - General Data Protection Regulation
- (COBIT) - Control Objectives for Information and Related Technologies
- (FedRAMP) - The Federal Risk and Authorization Management Program
- (ITAR) - International Traffic in Arms Regulations
- (AICPA) - American Institute of Certified Public Accountants
- (NERC CIP Standards) - NERC Critical Infrastructure Protection Standards
How many types of evasive testing are mentioned in this section?
Réponse : 3
What is the name of the security standard for credit card payments that a company must adhere to? (Answer Format: acronym)
Réponse : PCI-DSS
Lateral Movement
Si tout se déroule comme prévu et que nous parvenons à pénétrer le réseau de l’entreprise (Exploitation), à collecter les informations stockées localement et à élever nos privilèges (Post-Exploitation), nous passons à la phase de déplacement latéral. L’objectif est alors de tester les capacités d’un attaquant au sein du réseau. En effet, il ne s’agit pas seulement d’exploiter un système accessible au public, mais aussi d’obtenir des données sensibles ou de trouver tous les moyens de rendre le réseau inutilisable. Un exemple courant est celui des rançongiciels. Si un système du réseau est infecté, le rançongiciel peut se propager à l’ensemble du réseau. Il bloque tous les systèmes à l’aide de diverses méthodes de chiffrement, les rendant inutilisables pour toute l’entreprise jusqu’à la saisie de la clé de déchiffrement.
Dans la plupart des cas, l’entreprise est victime d’extorsion financière. C’est souvent à ce moment-là seulement que les entreprises prennent conscience de l’importance cruciale de la sécurité informatique. S’ils avaient disposé d’un bon expert en tests d’intrusion ayant effectué des vérifications (et mis en place des processus adéquats et une défense multicouche), ils auraient probablement pu éviter une telle situation et les dommages financiers, voire juridiques, qui en ont découlé. On oublie souvent que, dans de nombreux pays, les PDG sont tenus responsables de la protection insuffisante des données de leurs clients.
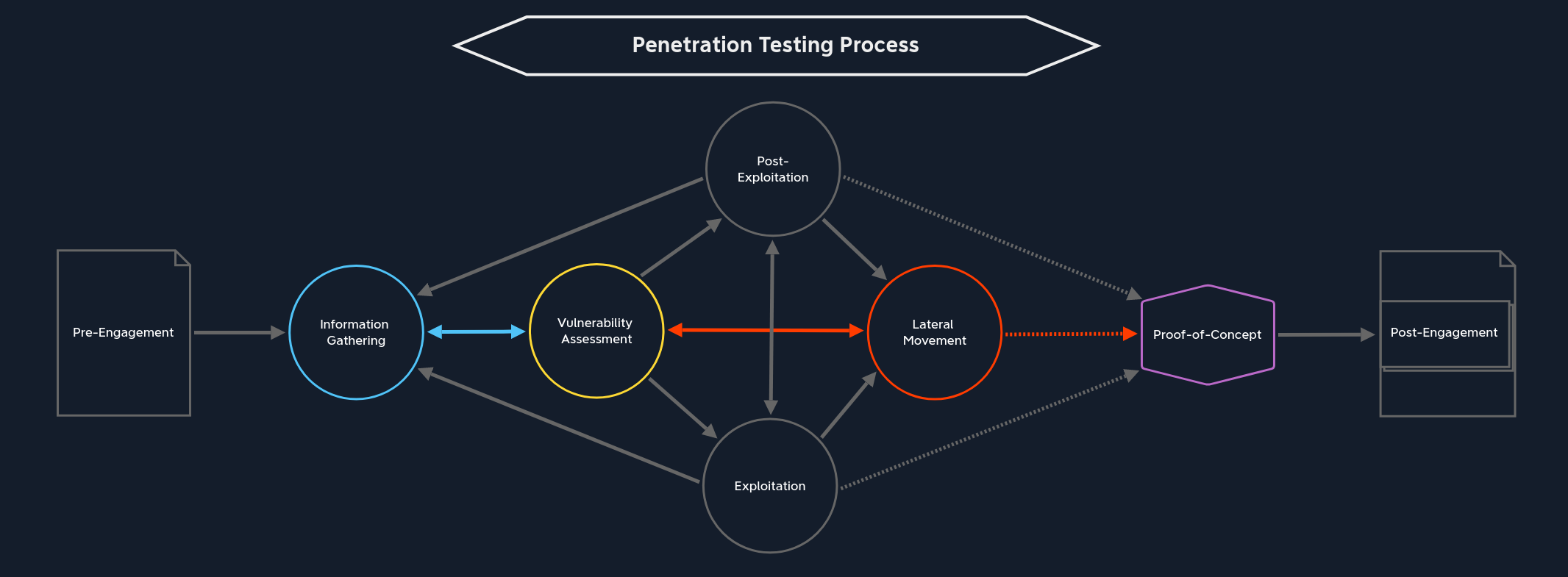
Dans cette étape, nous souhaitons tester l’étendue de notre exploration manuelle du réseau et identifier les vulnérabilités internes exploitables. Pour ce faire, nous procéderons en plusieurs phases :
1) Pivotement 2) Tests d’évasion 3) Collecte d’informations 4) Évaluation des vulnérabilités 5) Exploitation (privilèges) 6) Post-exploitation
Comme illustré dans le graphique ci-dessus, nous pouvons passer à cette étape depuis les phases d’exploitation et de post-exploitation. Il arrive que nous ne trouvions pas de moyen direct d’élever nos privilèges sur le système cible, mais nous disposons de techniques de déplacement au sein du réseau. C’est là qu’intervient le déplacement latéral.
Pivoting
Dans la plupart des cas, le système utilisé ne dispose pas des outils nécessaires pour énumérer efficacement le réseau interne. Certaines techniques permettent d’utiliser l’hôte compromis comme proxy et d’effectuer toutes les analyses depuis notre machine d’attaque ou une machine virtuelle. Ainsi, le système compromis représente et achemine toutes nos requêtes réseau envoyées depuis notre machine d’attaque vers le réseau interne et ses composants.
De cette manière, nous nous assurons que les réseaux non routables (et donc inaccessibles publiquement) restent accessibles. Cela nous permet de les analyser à la recherche de vulnérabilités et de pénétrer plus profondément dans le réseau. Ce processus est également connu sous le nom de pivotement ou tunnelage.
Un exemple simple : nous avons une imprimante à domicile non accessible depuis Internet, mais nous pouvons envoyer des travaux d’impression depuis notre réseau domestique. Si l’un des hôtes de notre réseau domestique est compromis, il pourrait être utilisé pour envoyer ces travaux à l’imprimante. Bien qu’il s’agisse d’un exemple simple (et improbable), il illustre l’objectif du pivotement : accéder à des systèmes inaccessibles via un système intermédiaire.
Evasive Testing
À ce stade, il convient également de déterminer si les tests d’évasion font partie du périmètre d’évaluation. Chaque tactique possède ses propres procédures, nous permettant de dissimuler ces requêtes afin de ne pas alerter les administrateurs et l’équipe de sécurité.
Il existe de nombreuses méthodes de protection contre les déplacements latéraux, telles que la (micro)segmentation du réseau, la surveillance des menaces, les systèmes IPS/IDS et EDR. Pour les contourner efficacement, il est essentiel de comprendre leur fonctionnement et leurs réactions. Nous pourrons alors adapter et appliquer des méthodes et stratégies permettant d’éviter la détection.
Information Gathering
Avant de cibler le réseau interne, il est essentiel d’obtenir une vue d'ensemble des systèmes accessibles depuis notre système et de leur nombre. Ces informations peuvent déjà nous être fournies suite à la dernière phase de post-exploitation, lors de laquelle nous avons analysé en détail les paramètres et la configuration du système.
Nous reprenons la phase de collecte d’informations, mais cette fois-ci depuis l’intérieur du réseau, avec une perspective différente. Une fois tous les hôtes et serveurs identifiés, nous pouvons les recenser individuellement.
Vulnerability Assessment
L’évaluation des vulnérabilités au sein du réseau diffère des procédures précédentes. En effet, les erreurs sont bien plus fréquentes au sein d’un réseau que sur les hôtes et serveurs exposés à Internet. Dans ce contexte, l’appartenance à un groupe et les droits d'accès aux différents composants du système sont essentiels. De plus, il est courant que les utilisateurs partagent des informations et des documents et collaborent à leur élaboration.
Ce type d’information nous est particulièrement précieux lors de la planification de nos attaques. Par exemple, si nous compromettons un compte utilisateur appartenant à un groupe de développeurs, nous pouvons accéder à la plupart des ressources utilisées par les développeurs de l’entreprise. Ceci nous fournira probablement des informations internes cruciales sur les systèmes et pourrait nous aider à identifier des failles ou à étendre notre accès.
(Privilege) Exploitation
Une fois ces chemins identifiés et priorisés, nous pouvons passer à l'étape d'accès aux autres systèmes. Nous trouvons souvent des moyens de déchiffrer les mots de passe et les hachages pour obtenir des privilèges plus élevés. Une autre méthode courante consiste à utiliser nos identifiants existants sur d’autres systèmes. Il arrive également que nous n’ayons même pas besoin de déchiffrer les hachages et puissions les utiliser directement. Par exemple, nous pouvons utiliser l’outil Responder pour intercepter les hachages NTLMv2. Si nous interceptons un hachage d’administrateur, nous pouvons utiliser la technique du « pass-the-hash » pour nous connecter en tant que cet administrateur (dans la plupart des cas) sur plusieurs hôtes et serveurs.
En définitive, l’objectif de la phase de déplacement latéral est de se déplacer au sein du réseau interne. Les données et informations existantes sont polyvalentes et souvent utilisées de multiples façons.
Post-Exploitation
Une fois que nous avons atteint un ou plusieurs hôtes ou serveurs, nous répétons les étapes de la phase post-exploitation pour chaque système. Nous collectons alors à nouveau les informations système, les données des utilisateurs créés et les informations commerciales pouvant servir de preuves. Toutefois, nous devons veiller à nouveau à la manière dont ces différentes informations doivent être traitées et aux règles définies dans le contrat concernant les données sensibles.
Enfin, nous sommes prêts à passer à la phase de validation de concept (PoC -> Proof of Concept) afin de démontrer notre travail et d’aider notre client, ainsi que les responsables de la remédiation, à reproduire efficacement nos résultats.
Cours complété