TryHackMe - Incident Response Fundamentals
Write-up de la room Incident Response Fundamentals qui nous parlera des réponses face aux incidents

Informations sur la room
Apprenez à effectuer une réponse aux incidents en matière de cybersécurité.
Lien : Incident Response Fundamentals
Objectifs d’apprentissage
Cette room couvre les compétences suivantes :
- Aperçu des incidents et de leur gravité
- Types d’incidents courants
- Phases de réponse aux incidents selon les référentiels SANS et NIST
- Outils de détection et de réponse aux incidents, ainsi que le rôle des guides pratiques
Plan de réponse aux incidents
Solutions des tâches
Task 1 - Introduction to Incident Response
Imaginez vivre dans une rue très dangereuse avec beaucoup d’objets de valeur chez vous. Vous envisagez sans doute d’avoir un agent de sécurité et quelques caméras de vidéosurveillance. Cacher ces objets de valeur dans une pièce souterraine cachée est une bonne idée si un intrus parvient à pénétrer chez vous. Voici les mesures à prendre pour assurer la sécurité de votre domicile, avant même toute attaque.
Outre ces mesures proactives, avez-vous déjà réfléchi à la situation si quelqu’un parvenait à contourner vos dispositifs de sécurité extérieurs et à pénétrer chez vous ? Vous devez également prendre plusieurs autres mesures après une attaque.
Task 2 - What are Incidents?
Plusieurs processus différents s’exécutent sur vos appareils informatiques, tels que vos ordinateurs portables, vos téléphones mobiles, etc. Certains de ces processus sont interactifs : vous effectuez des actions, comme jouer à un jeu ou regarder une vidéo. D’autres, non interactifs, s’exécutent en arrière-plan et ne nécessitent pas votre interaction. Ils sont simplement nécessaires à votre appareil. Ces deux types de processus génèrent plusieurs événements. Chaque action est consignée dans un journal.
Les événements sont générés en grand nombre et régulièrement. En effet, de nombreux processus s’exécutent sur un appareil, chacun effectuant des tâches routinières différentes, générant ainsi de nombreux événements. Ces événements peuvent parfois indiquer un problème grave sur votre appareil. Comment analyser ces nombreux événements et déterminer s’ils indiquent une activité nuisible ? Des solutions de sécurité existent pour résoudre ce problème. Ces événements sont enregistrés dans les solutions de sécurité sous forme de journaux, qui peuvent y détecter des activités nuisibles. Cela nous a grandement simplifié la tâche ! Mais attendez un instant; le véritable défi se situe après que la solution de sécurité ait détecté ces activités.
Ainsi, lorsqu’une solution de sécurité détecte un événement ou un groupe d’événements associé à une activité potentiellement dangereuse, elle déclenche une alerte. L’équipe de sécurité analyse ensuite ces alertes. Certaines de ces alertes peuvent être des faux positifs, tandis que d’autres sont des vrais positifs. Les alertes qui indiquent un danger sans être dangereuses sont appelées faux positifs. À l’inverse, les alertes qui indiquent un danger et sont réellement dangereuses sont appelées vrais positifs. L’exemple ci-dessous illustre mieux ce phénomène :
Faux positif: Une solution de sécurité a déclenché une alerte concernant un volume important de données transférées d’un système vers une adresse IP externe. Après analyse de cette alerte, l’équipe de sécurité a découvert que le système concerné était en cours de sauvegarde vers un service de stockage cloud, ce qui a provoqué ce phénomène. Il s’agit d’un faux positif.Vrai positif: Une solution de sécurité a déclenché une alerte concernant une tentative d’hameçonnage visant l’un des utilisateurs de l’organisation. Après analyse de cette alerte, l’équipe de sécurité a découvert que l’e-mail en question était un e-mail d’hameçonnage envoyé à cet utilisateur pour compromettre le système. Il s’agit d’un vrai positif.
What is triggered after an event or group of events point at a harmful activity?
Réponse : alert
If a security solution correctly identifies a harmful activity from a set of events, what type of alert is it?
Réponse : true positive
If a fire alarm is triggered by smoke after cooking, is it a true positive or a false positive?
Réponse : false positive
Task 3 - Types of Incidents
On qualifie généralement de tentative de piratage toute activité malveillante liée au monde numérique. C’est peut-être vrai, mais c’est très générique en matière de cybersécurité. Les incidents de sécurité peuvent être de différents types. Dans les tâches précédentes, nous avons vu un exemple d’alerte positive, devenue un incident après analyse par l’équipe de sécurité. Cet incident était lié à un e-mail d’hameçonnage, probablement accompagné d’une pièce jointe malveillante. Si elle est téléchargée dans le système, cette pièce jointe peut avoir des conséquences néfastes. Il s’agit d’un type d’incident parmi d’autres. Il en existe plusieurs autres, qui peuvent survenir indépendamment ou simultanément chez la même victime.
Malware Infections: Les logiciels malveillants sont des programmes malveillants qui peuvent endommager un système, un réseau ou une application. La majorité des incidents sont liés à des infections par des logiciels malveillants. Il existe différents types de logiciels malveillants, chacun ayant un potentiel de dommages spécifique. Les infections par logiciels malveillants sont principalement causées par des fichiers tels que du texte, des documents, des exécutables, etc.

Security Breaches: Les failles de sécurité surviennent lorsqu’une personne non autorisée accède à des données confidentielles (que nous ne souhaitons pas qu’elle voie ou ait accès). Les failles de sécurité sont primordiales, car de nombreuses entreprises dépendent de leurs données confidentielles, qui ne doivent être accessibles qu’au personnel autorisé.

Data Leaks: Les fuites de données sont des incidents au cours desquels les informations confidentielles d’un individu ou d’une organisation sont exposées à des entités non autorisées. De nombreux attaquants exploitent ces fuites de données pour nuire à la réputation de leurs victimes ou utilisent cette technique pour les menacer et obtenir ce qu’ils veulent. Contrairement aux failles de sécurité, les fuites de données peuvent également être causées involontairement par des erreurs humaines ou des erreurs de configuration.

Insider Attacks: Les incidents internes à une organisation sont appelés attaques internes. Imaginez un employé mécontent qui infecte l’ensemble du réseau via une clé USB lors de son dernier jour. Il s’agit d’un exemple d’attaque interne. Une personne au sein de votre organisation qui lance intentionnellement une attaque entre dans cette catégorie. Ces attaques peuvent être dangereuses, car une personne interne a toujours un meilleur accès aux ressources qu’une personne externe.

Denial Of Service Attacks(DoS) : La disponibilité est l’un des trois piliers de la cybersécurité. Les solutions de sécurité défensives et les individus cherchent constamment des moyens de protéger les informations ; elles garantissent l’accès simultané des données. En effet, il est inutile de protéger ce qui nous est inaccessible. Les attaques par déni de service (DoS) sont des incidents où l’attaquant inonde un système, un réseau ou une application de fausses requêtes, le rendant ainsi inaccessible aux utilisateurs légitimes. Cela se produit en raison de l’épuisement des ressources disponibles pour traiter les requêtes.

Tous ces incidents ont un potentiel unique d’impact négatif sur la victime. Leur gravité est incomparable. En effet, un incident peut être désastreux pour une organisation et causer des dommages mineurs à une autre.
Par exemple, la société XYZ pourrait ne pas être gravement touchée par une fuite de données, car les informations qu’elle stocke peuvent être inutiles pour quiconque. En revanche, elle pourrait subir des pertes considérables en cas d’attaque par déni de service (DoS) sur son site web principal, car ses services dépendent de ce site.
A user’s system got compromised after downloading a file attachment from an email. What type of incident is this?
Réponse : malware infection
What type of incident aims to disrupt the availability of an application?
Réponse : Denial of service
Task 4 - Incident Response Process
Le cadre de réponse aux incidents SANS comporte 6 phases, que l’on peut appeler « PICERL » pour les mémoriser facilement.
| Phase | Explanation | Example |
|---|---|---|
| Preparation | This is the first phase. The preparation phase includes building the necessary resources to handle an incident. These resources include developing incident response teams, having a proper incident response plan in place, and deploying necessary security solutions to combat the incidents. | Conducting awareness training for employees on phishing emails. Phishing emails are fraudulent emails sent by malicious attackers that can trick you into performing actions that can lead you to an incident. |
| Identification | The identification phase refers to looking for any abnormal behavior that may indicate an incident. This involves using various security solutions and techniques to monitor abnormal events. | The security team notices a huge amount of data being sent out from one of the hosts. Upon analysis, it was found to be compromised after a malicious file was downloaded from a phishing email attachment. |
| Containment | Once an incident has been identified, the next step should be to contain it. This means minimizing the impact of the attack. This is usually done by isolating the victim machine, disabling the compromised user accounts, etc. | The Security team isolates the host from the network to minimize the impact and not allow the attacker to jump to other systems, leveraging the compromised host. |
| Eradication | This phase, as its name suggests, involves removing the threat from the attacked environment. The threat may be of any kind. The eradication phase will ensure the subject environment is clean, and now we can move to the recovery phase. | A deep malware scan was executed on the system to remove the malicious software from the host. |
| Recovery | The recovery phase is very important in this chain. It involves recovering the affected systems from backup or rebuilding them. The recovered systems are then tested and are ready to use. | The compromised host was re-configured, and the exfiltrated data was restored from the backup. |
| Lessons Learned | This is also an important part of the incident response lifecycle. Gaps in the detection and analysis of the incident are identified and documented, helping to improve the overall process in future incidents. | Conducting a post-incident review meeting to analyze the incident’s root cause and improve the security to prevent future attacks. |
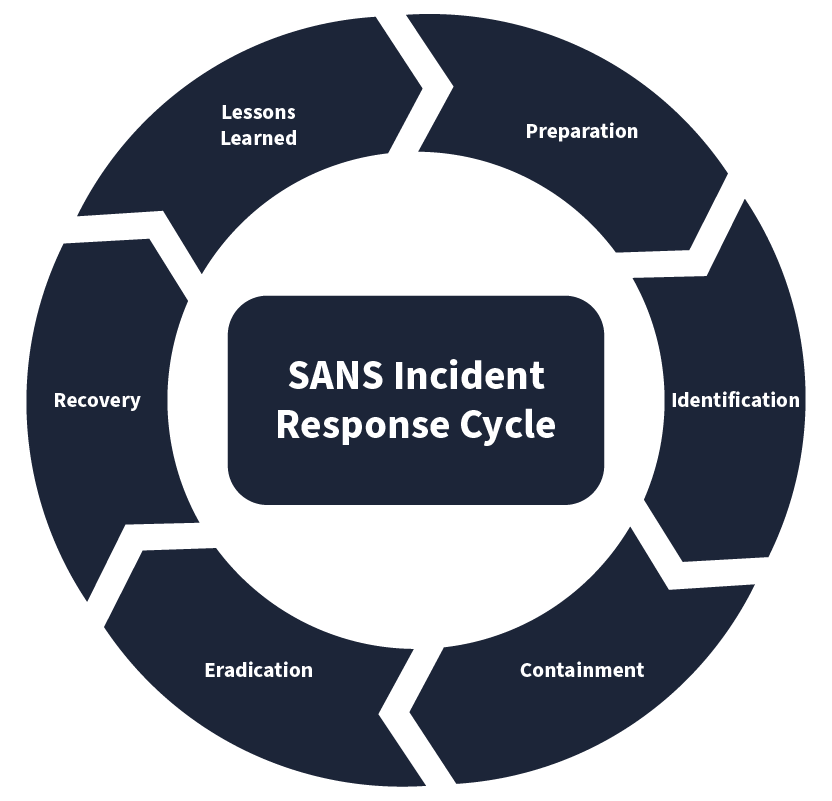
Le cadre de réponse aux incidents du NIST est similaire au cadre SANS étudié précédemment. Le nombre de phases y est réduit à quatre.

Et voici la comparaison des deux :

Les organisations peuvent élaborer leurs processus de réponse aux incidents en suivant ces cadres. Chaque processus est doté d’un document formel répertoriant toutes les procédures organisationnelles pertinentes. Ce document formel de réponse aux incidents est appelé Plan de réponse aux incidents. Ce document structuré décrit la démarche à suivre lors de tout incident. Il est formellement approuvé par la direction et comprend les procédures à suivre avant, pendant et après un incident.
Les principaux éléments de ce plan comprennent (liste non exhaustive) :
- Rôles et responsabilités
- Méthodologie de réponse aux incidents
- Plan de communication avec les parties prenantes, y compris les forces de l’ordre
- Procédure d’escalade à suivre
The Security team disables a machine’s internet connection after an incident. Which phase of the SANS IR lifecycle is followed here?
Réponse : containment
Which phase of NIST corresponds with the lessons learned phase of the SANS IR lifecycle?
Réponse : Post Incident Activity
Task 5 - Incident Response Techniques
Nous avons étudié la deuxième phase du cycle de réponse aux incidents : « Identification » dans le SANS et « Détection et analyse » dans le NIST. Il est très difficile de détecter les comportements anormaux et d’identifier les incidents manuellement. Il existe plusieurs solutions de sécurité qui remplissent chacune leur rôle spécifique dans la détection des incidents. Certaines d’entre elles sont même capables de répondre aux incidents et d’exécuter les autres phases du cycle de vie, telles que le confinement, l’éradication, etc. Voici une brève explication de certaines de ces solutions :
SIEM: La solution de gestion des informations et des événements de sécurité (SIEM) centralise tous les journaux importants et les corrèle pour identifier les incidents.AV: L’antivirus (AV) détecte les programmes malveillants connus dans un système et les analyse régulièrement.EDR: La détection et la réponse aux points d’extrémité (EDR) sont déployées sur chaque système, le protégeant contre certaines menaces avancées. Cette solution peut également contenir et éradiquer la menace.

Une fois les incidents identifiés, certaines procédures doivent être suivies, notamment l’analyse de l’étendue de l’attaque et la prise des mesures nécessaires pour prévenir d’autres dommages et les éliminer à la racine. Ces étapes peuvent varier selon le type d’incident. Dans ce cas, disposer d’instructions étape par étape pour gérer chaque type d’incident permet de gagner un temps précieux. Ces instructions sont appelées « playbooks ».
Les playbooks constituent les lignes directrices d’une réponse complète aux incidents.
Voici un exemple de playbook pour un incident : E-mail d’hameçonnage
Avertir toutes les parties prenantes de l’incident d’e-mail d’hameçonnage
Déterminer si l’e-mail était malveillant en analysant l’en-tête et le corps de l’e-mail
- Rechercher et analyser les pièces jointes
- Déterminer si quelqu’un les a ouvertes
- Isoler les systèmes infectés du réseau
- Bloquer l’expéditeur de l’e-mail
Les runbooks, quant à eux, décrivent en détail, étape par étape, les étapes spécifiques à suivre lors de différents incidents. Ces étapes peuvent varier en fonction des ressources disponibles pour l’investigation.
Step-by-step comprehensive guidelines for incident response are known as?
Réponse : Playbooks
Task 6 - Lab Work Incident Response
Scénario : Dans cette tâche, vous allez déclencher un incident en téléchargeant une pièce jointe d’un e-mail de phishing. Cette pièce jointe est un logiciel malveillant. Une fois le fichier téléchargé, un incident se produit. Vous allez maintenant commencer à l’examiner. La première étape consiste à identifier le nombre d’hôtes infectés par ce même fichier, car il est fort probable qu’une même campagne de phishing cible plusieurs employés au sein d’une même organisation. Vous verrez des hôtes sur lesquels ce fichier a été exécuté après son téléchargement et d’autres sur lesquels il a été simplement téléchargé. Vous effectuerez les actions nécessaires sur chacun de ces hôtes et consulterez une chronologie détaillée des événements sur l’hôte infecté.
What was the name of the malicious email sender?
Réponse : Jeff Johnson
What was the threat vector?
Réponse : Email Attachment
How many devices downloaded the email attachment?
Réponse : 3
How many devices executed the file?
Réponse : 1
What is the flag found at the end of the exercise?
Réponse : THM{My_First_Incident_Response}
Task 7 - Conclusion$
Dans ce cours nous avons pu voir les différents concept de SANS et NIST qui sont très important dans la défense de la cybersécurité
Room Complétée